

未来算力:NVIDIA GB200 NVL72概览
发布者:兆龙互连
发布时间:2025-03-04



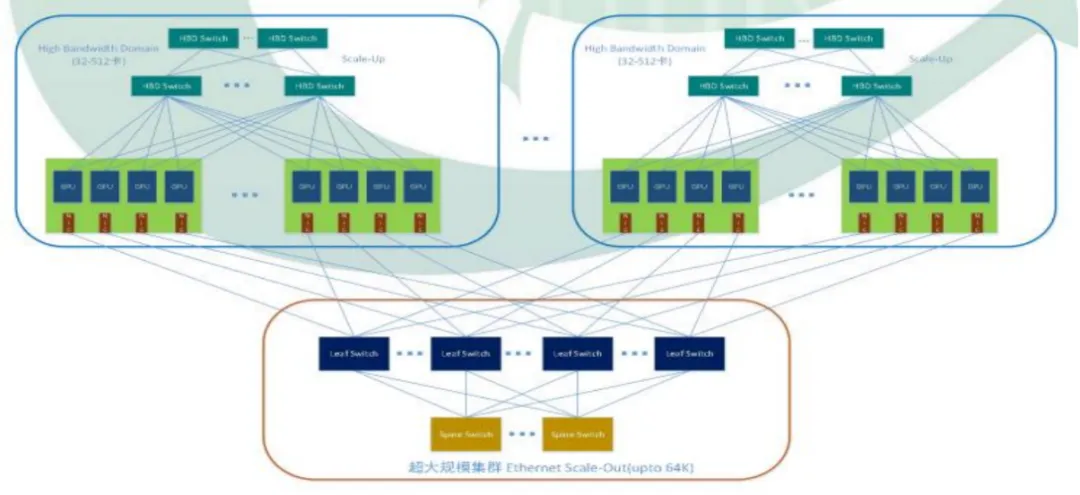
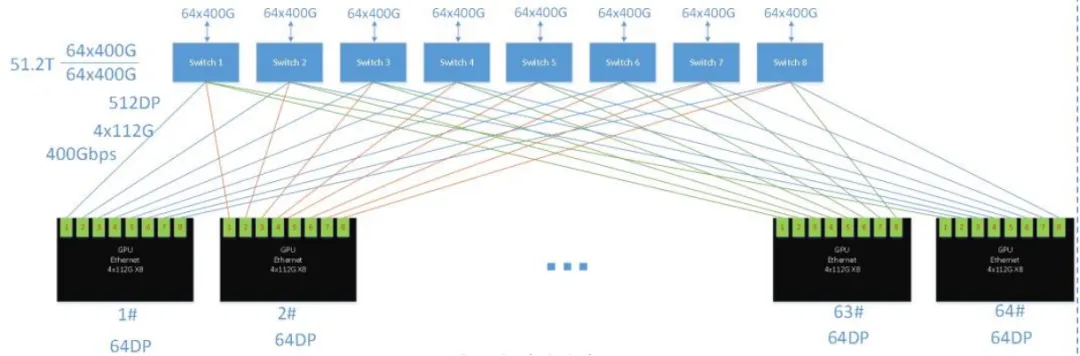
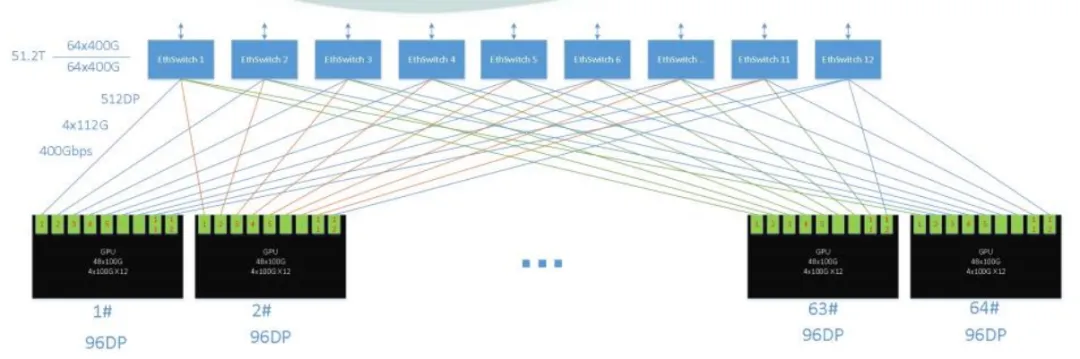

你可能感兴趣的新闻
-
 兆龙互连亮相第四届先进制造业信息化发展论坛,助力打造智算连接新可能
兆龙互连亮相第四届先进制造业信息化发展论坛,助力打造智算连接新可能2026-06-01
-
 兆龙互连承办高速铜缆系列团体标准研讨会议
兆龙互连承办高速铜缆系列团体标准研讨会议2026-05-17
-
 兆龙互连全国城市合伙人招募,火热开启!
兆龙互连全国城市合伙人招募,火热开启!2026-04-29
-
 一图读懂兆龙互连2025年年度报告暨2026年第一季度报告
一图读懂兆龙互连2025年年度报告暨2026年第一季度报告2026-04-29
-
3月25日-27日,兆龙互连邀请您参加中国(上海)机器视觉展
2026-03-18


解决方案
白皮书
相关产品
